Model Evaluation
This page is under development...
What is "eval"?
"Eval" stands for evaluation. Unlike "evaluation" in social impact projects, which typically refers to impact evaluation, "eval" in the context of GenAI usually refers to the systematic assessment of the performance of large language models (LLMs) and their associated applications.
We recently published a blog post on an AI evaluation framework for the development sector. This framework expands the technical model evaluation of an AI tool to a whole journey of model evaluation, product evaluation, user evaluation, and impact evaluation.
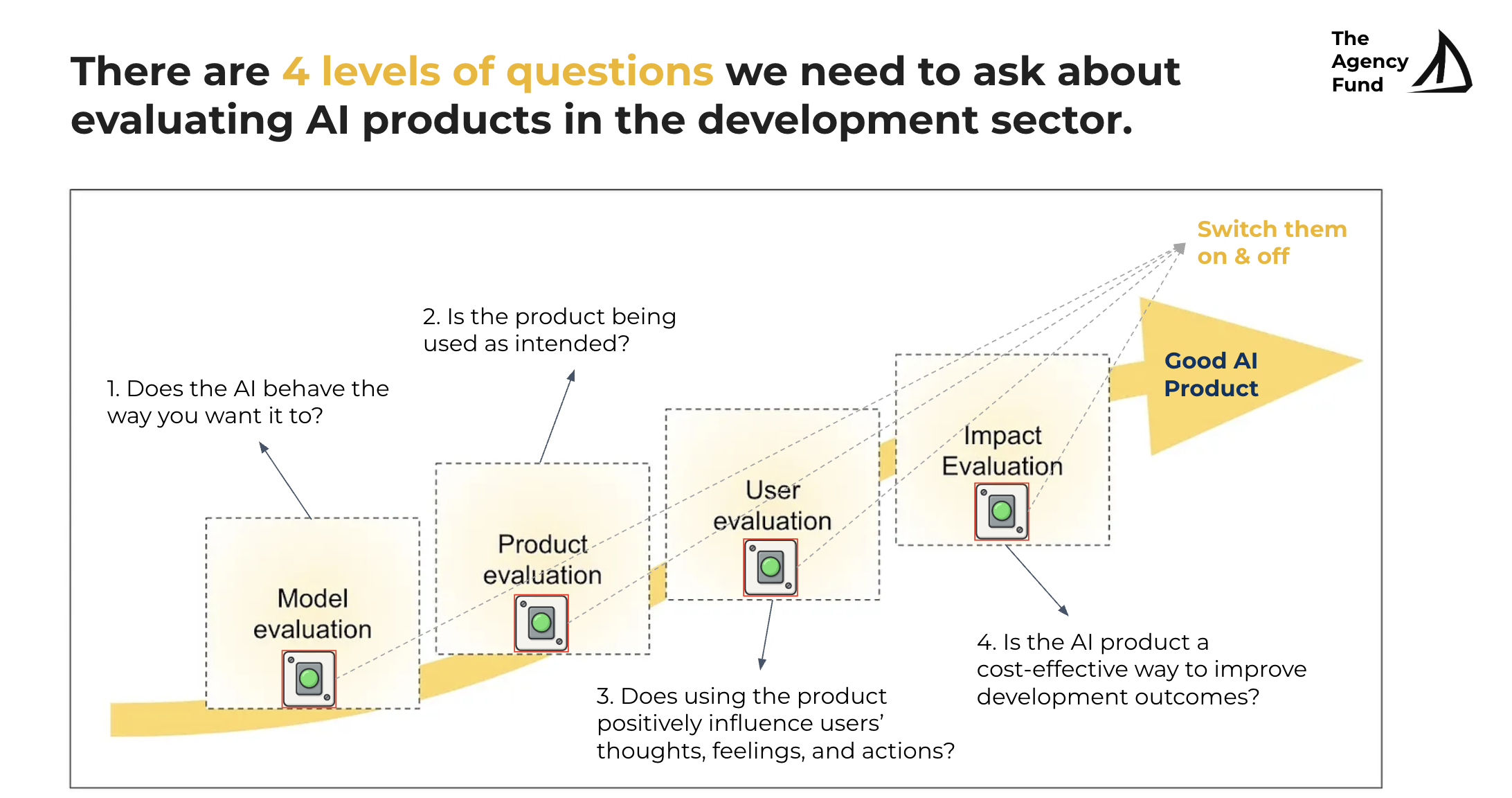
What is our process of evaluation?
Model Evaluation
This section is under development...
We conduct our model evaluations on Confident-AI using the Deepeval Framework, which is an open-source framework for evaluating large language models (LLMs). The framework provides a comprehensive set of tools and metrics to assess the performance of LLMs across various tasks and domains.
As a first step, we focused on answer relevancy from the RAGAS metrics. Answer relevancy focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information and higher scores indicate better relevancy.
Similar to our strategy to building the knowledge base, we build a core evaluation database that is applicable to all contexts, and then develop context-specific evaluation databases in collaboration with our NGO and academic partners.
For the core evaluation database, we design the golden question-answer pairs based on the following categories:

Reference: Please see this post for a comprehensive review of LLM evals.